简介:
来自于Ubuntu自带文档上的介绍:
1 | add-apt-repository is a script which adds an external APT repository to |
来自百度百科的介绍:
1 | add-apt-repository的提供方python-software-properties ,平台是Ubuntu Karmic (9.10)。 |
1 | add-apt-repository is a script which adds an external APT repository to |
1 | add-apt-repository的提供方python-software-properties ,平台是Ubuntu Karmic (9.10)。 |
mongodb是一个基于分布式文件存储的数据库。由c++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。
mongoab是一个介于关系型数据库和非关系型数据库之间的产品,是非关系型数据库当中功能丰富,最像关系型数据库的一个产品。它支持的数据格式有json,bson等。他最大的特点是它的查询语法类似于面向对象语言。并且它还支持对数据创建索引。
下面的图片是百度百科对mongodb的介绍
在mongodb中是通过数据库、集合、文档的方式来管理数据的。下边是mongodb与关系型数据库的一些概念比较图。
和关系型数据库一样,mongodb允许一个实例创建多个数据库,一个数据库创建多个集合,一个集合创建多个文档
mongodb使用CS架构开发。client shell使用链接命令如下:1
mongodb://[username:password@]host1[:port1][,host2[:port2],...[,hostN[:portN]]][/[database][?options]]

show dbs: 查询所有数据库信息
db
use 库名
使用指定的库,没有则创建(注意:当使用一个新建的库,而且没有插入任何数据时。此时的库实际没有被创建。)
db.dropDatabase
db.createConllection(name,options)
name:表示集合的名称
options:表示创建参数
db.
db.
document:表示文档,可以是json类型的数据格式
db.
db.test_collection.update({“age”:18},{$set:{“name”:”wan”,”age”:16}},{multi:true})
test_collection:集合名称
{“age”:18} :查询结果
{$set:{“name”:”wan”,”age”:16}} 修改条件
{multi:true}:参数 multi 为true时表示修改全部,false时表示修改第一个匹配的文档。默认为false
db.
删除前最好先执行查询
db.
query :查询条件
projection:投影查询key
投影查询
db.test_collection.find({“age”:18},{name:1,age:1,address:1,_id:0})
test_collection:制定的集合
{“age”:18} :查询条件
{name:1,age:1,address:1,_id:0} :投影参数,个人不明白只有_id可以设置为0,如果别的设置为0会报Projection cannot have a mix of inclusion and exclusion.异常
1 | db.createUser({ |
1 | db.updateUser( |
1 | show users |
1 | db.dropUser("spiderBao1") |
1 | db.changeUserPassword("test1","123") |
JSR-303 实现方案+JSR-349Bean 验证
JSR-303的实现使用hibernate的实现 @Valid注解
JSR-349Bean 验证的实现使用spring提供的@Validated注解
本案例的环境为,springboot2.0.5.RELEASE
基础代码实现:
导入坐标
1 | <dependency> |
此坐标包含了@Valid 和@Validated
创建入口启动类
1 | package com.healthengine.department; |
注意:此入口启动类要放在Controller包的同级目录下,因为@SpringBootApplication注解会扫描同级目录及其子目录。此类只放在java目录下是不对的。要放在Java目录下的下级目录下
 (正确目录格式)
(正确目录格式)
 (错误目录格式)
(错误目录格式)
配置文件设置
1 | server: |
创建controller
案例使用到的java Bean
1 | package com.healthengine.medpro.company; |
1 | package com.healthengine.medpro.department; |
1 | package com.healthengine.medpro.company; |
1 | //对象参数校验 |
在类中加入@Validated
1 | () |
方法上对参数使用校验注解
1 | ("/test2") |
创建分组标识接口
1 | public interface AddDepartment { |
在要校验的字段上使用校验注解并添加groups属性
1 | (message = "用户名不能为空!",groups = {AddDepartment.class}) |
在方法上使用校验
1 | ("/test3") |
在要需要嵌套校验的对象上添加@valid
1 | /** |
在方法上使用
1 | ("/test4") |
1 | ("/test4") |
1 | package com.healthengine.department.exception; |
使用hibernate参数校验注解后发现,使用Spring jpa 存入数据时也会产生校验。
目前解决方案,使用注解时为其分组。这样可以解决存入数据库时的校验,当存入数据库前,想做校验需要自己手动编写逻辑。
概念:
jodconverter的全称是 java Document Converter ,它可以在不同的办公室格式之间转换文档。它利用了Apache OpenOffice或LibreOffice,
JODConverter自动执行OpenOffice / LibreOffice支持的所有转换。支持的转化包括:
| 文件类型 | 输入格式 | 输出格式 |
|---|---|---|
| 文本 | DOC,DOCX,ODT,OTT,RTF,TEXT | DOC,DOCX,HTML,ODT,OTT,PDF,PNG,RTF,TXT |
| 电子表格 | CSV,ODS,OTS,TSV,XLS,XLSX | CSV,HTML,ODS,OTS,PDF,PNG,TSV,XLS,XLSX |
| 介绍 | ODP,OTP,PPT,PPTX | HTML,ODP,OTP,PDF,PNG,PPT,PPTX,SWF |
| 画画 | ODG,OTG | ODG,OTG,PDF,PNG,SWF |
| 其他 | HTML | DOC,DOCX,HTML,ODT,OTT,PDF,PNG,RTF,TXT |
要使用JODConverter,您需要:
此属性设置将用于执行文档转换的办公室安装的office主目录。
当JODConverter需要处理已启动的办公流程时,将使用流程管理器。当JODConverter启动办公室进程时,它必须检索已启动进程的PID,以便以后能够在需要时终止它。
默认值:默认情况下,JODConverter将根据运行JODConverter的操作系统尝试查找最佳进程管理器。但是,如果在类路径中找到,则可以使用任何实现ProcessManager接口的进程管理器。
只有在启用了processManager后才可以使用jodconverter进行文件转换
其余属性请查看此链接https://github.com/sbraconnier/jodconverter/wiki/Configuration
1 | File inputFile = new File("document.doc"); |
1.java 语言的前身是Oak语言
2.Oak是由美国公司 Sun Microsystems 在1991年推出的
3.1995年Sun公司将Oak语言改名为Java语言
4.2009年Oracle公司将Sun收购,所以迄今为止java的版本更新由Oracle发布.
5.Java语言有三大版本,来解决现如今主流方向的编程问题.那就是:
a) java 2 Platform standard Edition 简称 j2SE 标准版本,可用于一些桌面程序的开发
b) java 2 Platform Enterprise Edition 简称 j2EE 企业级版本,可以跟tomcat等一些web容器配合开发网站
c) java 2 Platform Micro Edition 简称 j2ME 微型版本,可用于一些小型的计算机系统中,如开发手机的移动应用程序.
1.Java与C++同是面向对象的编程语言,C++的执行效率高于java.但java比C++更易于编程开发
2.java语言相比C++来说在web方面更有优势,因为java2EE在web领域目前是主流,一般的企业级网站建设都使用J2EE
3.因为jvm具有稳定的可靠性所以java语言是安全可靠的
1.java实现跨平台的主要因素是 jvm(java Virtual Machine)
2.jvm是一台虚拟机,java通过它可以操纵平台的机器指令集.所以在不同的平台下下载不同的jvm就可实现java语言的跨平台性.
个人总结 Java之所以能实现跨平台就是有jvm这个中间过渡层的虚拟机.而别的没有这个过渡层的编译性语言只能依赖固定的平台
1.JIT (just in time):JIT是一种提高程序运行效率的方法。通常,程序有两种运行方式:静态编译与动态解释。静态编译的程序在执行前全部被翻译为机器码,而动态解释执行的则是一句一句边运行边翻译。
2.为什么Java会引入JIT即时解释器?因为java要提高程序的运行效率.大家都知道java语言编写后的文件是.java文件,要想被jvm识别并使用需要经过javac编译成.class 文件也就是所谓的(字节码文件).然后jvm解析字节码文件时原先是逐行解释为平台的机器指令集的,这样做就存在了二次编译解析的过程,java为了提高效率引入JIT将类或类中的一些常用代码指定为热点代码(hot prot code),jvm将这些热点代码转化成于本地平台先关的机器码后并存储起来,下次遇到后直接使用来提高程序的运行效率
1.语言级多线程功能
1.java执行代码在运行时是动态载入的,在客户机网络允许的情况下,通过自动更新版本的方式来实现瘦客户机框架的目的.
2.Java提供的类库及其API种类很多,所以使用开发我们可以站在居然肩膀上进行,节省了一些不必要的操作.
本人使用的系统是Ubuntu的,所以使用了apt install 安装了openjdk,安装路径在/usr/lib/jvm下,我创建了软链接到/usr/bin下所以或默认配置到系统的环境变量中.关于系统环境变量可查看Linux-文件配置篇
1.Java程序是由类构成的,程序的入口方法是main()
2.Java程序文件扩展名是.java,编译后生成的字节码文件的扩展名是.class1
2
3
4
5
6
7
8
9class HelloWorld{
public static void main(String[] args){
System.out.println("Hello World!");
for (int i = 0;i < args.length;i++){
System.out.println("args["+i+"]:"+args[i]);
}
}
}
3.一个文件中只能有一个公共类,该类的名字即使文件的名字
4.执行程序时,程序名之后输入的内容称为命令行参数,这些参数将会放入main(String[] args)中的args字符串数组中
5.Java语言区分大小写
1.面向对象是一种软件开发的方法.在面向对象程序设计方法出现之前,软件界广泛流行的是面向过程的设计方法
2.面向对象技术相比面向过程而言,可以使程序变得更简单易于理解.还有就是可以更大化的实现代码的重用
3.面向对象方法学,可以简单理解为.一个能使分析,设计和实现更接近人们的认识的学科
4.面向对象方法学主要包括3个方面
1.面向对象分析(object-oriented Analysis)简称OOA
2.面向对象设计(object-oriented Design)简称OOD
3.面向对象编程(object-oriented Programming)简称OOP
1.一个类的实例可以称为对象或实例
2.对象是类的一个具象,类是对象的一个抽象
3.OOP技术把问题看成是相互作用的事物的集合,也就是对象的集合.对象具有两个特性,一是状态,二是行为.状态是指对象本身的信息也就是属性,行为是实现对对象的操作也就是方法
4.OOP三大核心概念:封装、继承、多态
封装:封装体现的特点是将对象的属性和方法实现的细节隐藏起来,并报露出使用的入口
继承:将一个类中数据和方法保留,并加上自己特殊的数据和方法,从而构成一个新类。继承体现的是一种层次关系
多态:在一个或多个类中,可以让多个方法使用同一个名字。多态可以保证对不同数据类型进行同等的操作
在java程序中,换行符及回车符等都可以表示一行的结束且留有空白的部分都表示空白
注释不能插在一个标识符或关键字的中间
使用/*表示注释的开始,*/表示注释的结束位置
一般这种注释用于解释方法中的逻辑说明或方法说明
/**以/** 开始,*/结束
一般这种注释用于说明公共的类或方法
其中注释有一下参数:
@param 参数
@return 输出(返回值)
@throws 异常抛出
语句是java程序运行中的最小执行单元
程序的各语句之间需要使用;分隔
语句分为单语句及复合语句。单语句就是通常意义下的一条语句,复合语句是块(使用{}包裹起来的内容)
1 | //复合语句 |
abstract boolean brack byte case
catch char class const continue default
do double else extends false final
finally flost for future generic goto
if implements import inner instanceof int
interface long native new null operator
outer package private protected public rest
return short static strictfp super switch
synchronized this throw throws transient true
try var void volatile while
在java编程语言中,标识符由字母、下划线_、美元符号$、字母等构成
数子不能做为标识符的首个字母
标识符可以用在类上、接口上、方法上、变量上
1.缩进
2.变量的大小写
3.常量的大小写
3.方法名的应用
4.合理的注解和空格

整型常量默认使用int
整型量可用十进制、八进制或十六进制形式表示,以1~9开头的整数为十进制的表示形式。以0开头的数为八进制的表示形式。以0x或0X开头的数为十六进制的表示形式。

float表示单精度浮点数类型
double表示双精度浮点数类型
浮点数类型的常量默认情况下使用double


单个字符使用char来表示,一个char表示一个Unicode字符。char类型的常量必须使用一对‘’括起来

java 中boolean的值只有true or false 。
true or false 使用小写表示,计算机内部使用8位二进制表示
一般数组指的是一个对象
简介:表达式由运算符和操作数组成。表达式用来运算得出结果
java运算按功能可划分为:算术运算符、关系运算符、逻辑运算符、位运算符、赋值运算符和条件运算符、数组下标运算符
可以用来做操作数的有以下元素:
简介:常量可以简单理解为拥有单一不变唯一值引用
example:
1 | System.out.println(23.59); |
简介:变量是存储数据的基本单元,变量在使用之前需要先声明。使用时必须要为其初始化值
1 | double d1; |
方法内声明的变量称为:自动变量、局部变量、临时变量、或栈变量
类中定义的变量称为:类成员变量
方法内声明的变量是不存在默认值的,而类中声明的变量在类的初始化时会为其初始化默认值
类成员变量:各基本类型的默认值
| 类型 | 初始值 | 类型 | 初始值 |
|---|---|---|---|
| byte | 0 | double | 0.0 |
| short | 0 | char | ‘\u0000’ |
| int | 0 | boolean | false |
| long | 0l | 所有引用类型 | null |
| float | 0.0f |
1 | int xTest = (int)(Math.random()*100),yValue,zVar; |
变量的作用域
可以正常执行
1 | class Customer{ |
不可以正常执行
1 | class Customer{ |
由于Math类下的数学函数的返回值是基本数据类型或引用类型所以它们也可以被当做操作数来看待。
如下列举一些方法:
Math.sin();
Math.cos();
算术运算符如:
| 符号 | 表示 |
|---|---|
| + | 加法运算 |
| - | 减法运算 |
| * | 乘法运算 |
| / | 除法运算 |
| % | 取模运算(取余数) |
| ++ | 加1 |
| – | 减1 |
这里需要说明下 ++i 和i++的区别,++i在i被使用前加1,i++在i被使用后加1.–与++类似。
Java数据类型自动转换规则:
byte short char int long float double
排在前面的可以自动转换为后面的类型,如果要想将后面的类型转换为前面的类型需要使用强制类型转换(注意强制类型转换有可能损失精度,不建议使用)
不同类型数据进行运算时,java会将类型根据Java数据类型自动转换规则将类型统一,然后进行相应的运算。
| 符号 | 表示 |
|---|---|
| > | 大于 |
| >= | 大于且等于 |
| < | 小于 |
| <= | 小于且等于 |
| == | 等于 |
| != | 不等于 |
| 符号 | 表示 |
|---|---|
| & | 与 |
| | | 或 |
| && | 短路与 |
| || | 短路或 |
上表中的短路表示当判断的左边不满足整个逻辑运算符的规定时就会停止右边的逻辑运算并返回左边的逻辑值。如&&当左边是false时整个逻辑式的结果为false,因为&&是与只有两边都为true时才会返回true
位运算符是用来对二进制位进行操作的。位运算符只能对整型和字符串型数据进行操作
拥有算术意义的位运算符
| 符号 | 表示 |
|---|---|
| >> | 右移x位就表示除以2的x次方 |
1 | System.out.println(128>>1); |
拥有算术意义的赋值运算符
| 符号 | 表示 |
|---|---|
| += | 如x +=2 同 x = x + 2 |
| -= | 如x -= 2 同 x = x - 2 |
| *= | 如x =2 同 x = x 2 |
| /= | 如x /=2 同 x = x / 2 |
| %= | 如x %=2 同 x = x % 2 |
| >>= | 如 x >>=2 同 x = x >> 2 |
| 符号 | 表示 |
|---|---|
| ? : | 如x = condition?1:2 ,当condition为true时x值为1,相反为false时x值为2 |
1 | boolean condition = true; |
点用算符用来调用对象的变量值或使用方法等
new运算符用来创建一个类的实例(对象)
下标运算符用来获取序列中某个位置的值。
用于判断当前实例是否属于某个类或接口
1 | Father expression = new Expression(); |
注意 instanceof只能在对象和要判断的类之间存在继承或实现同一接口时做运算。不然会有语法错误提示
简介:一个java程序是由一个或多个.java文件组成的,.java文件被称为源文件。源文件可以是一个或多个类或接口,但是类中只能有一个公共类也就是public修饰类,并且源文件名要和公共类名一致。
java程序结构中的注意项:
简介:包是类的容器,程序设计人员利用包来划分名字空间,避免类名冲突。使用包的目的是将源文件有效的组织起来。
注意事项:
代码案例(example):
1 | package com.spider.dome |
简介:其作用就是将指定的资源引入当前类中,其实不使用引入语句直接使用其资源的全限定名称(报名.资源名)也是可以使用的。
注意事项:
代码案例(example):
1 | //引入当包下的全部 |
1 | Cat cat = new Cat(); |
简介:把一个值赋值给一个变量这样的语句就称为赋值语句
注意事项:
1 | Customer customer = new Customer(); |
简介:分支在java程序中分为2种 if 和 switch
if (单重分支)的语法形式如下:
if(条件表达式){
语句1;
}
if else 的语法形式如下:
if(条件表达式){
语句1;
}else{
语句2;
}
案例代码(example):
1 | private static void ifOrSwitchLearn(int firstVal,int secondVal){ |
switch 语句(多重分支)的语法形式如下:
switch (表达式){
case c1:
语句组1;
break;
case c2:
语句组2;
break;
…
case ck:
语句组k;
break;
default:
语句组;
break;
}
switch 语句中的break是可选项,程序运行到break处时会跳出当前switch语句块。没有遇到时会向下执行。
1 | int firstVal = 1; |
if else if 语句:
if else if 类似与 switch 每一项加了break的做法。
1 | if(firstVal==0){ |
简介:循环语句控制程序流程多次执行一段代码。java中提供了三种循环语句分别是 for wile do.
for 语句语法形式如下:
for(初始语句;条件表达式;迭代语句){
循环体语句;
}
注意事项:
1 | private static void forAndWileAndDoLearn(){ |
while 语句语法形式如下:
while(条件表达式){
循环体语句;
}
1 | private static void forAndWileAndDoLearn(){ |
do 语句语法形式如下:
do{
循环体语句;
}while(条件表达式);
1 | private static void forAndWileAndDoLearn(){ |
注意事项:
简介:标号可以放在任意语句之前,通常与for、while或do配合使用。
简介:break 用于跳出当前语句块
简介:跳过当前循环
1 | private static void learnOfBreakAndContinue(){ |
1 | Scanner scanner = new Scanner(System.in); |
在java中将程序运行可能遇到的错误分为2类,一类是非致命性的被称之为异常(expection),另一类是致命性的被称为错误(error)
异常是可以通过cache来处理的而错误则不可以。
异常处理时需要考虑的问题有,如何处理异常、异常是由谁来处理、异常对程序构成的影响是否在可控范围
简介:程序执行期间发生的严重事件的后果。例如FileNotFoundException
简介:通常程序中逻辑错误的结果。例如:ClassCastException
注意事项:
简介:类的定义也就是类的声明。简单来说分别是数据成员变量和成员方法。下面是类的语法书写格式
修饰符 class 类名 [extends 父类名]{
修饰符 变量类型 变量名;
修饰符 返回值类型 方法名( 参数列表){
方法体;
}
}
java中的访问权限修饰符表:
| 类型 | 无修饰符(public) | private | protected | public |
|---|---|---|---|---|
| 同一类 | yes | yes | yes | yes |
| 同一包中的子类 | yes | no | yes | yes |
| 同一包中的非子类 | yes | no | yes | yes |
| 不同包中的子类 | no | no | yes | yes |
| 不同包中的非子类 | no | no | no | yes |
总结点:
先看匿名内部类的定义的语法格式:
1 | new 实现接口() |
1 | new 父类构造器(实参列表) |
为什么匿名内部类的定义有这两种方式呢?这是因此这两种方式的定义分别对应两种方式,一种是接口,另一种是抽象类。
对于实现接口,由于接口是没有构造函数的,注意这里一定是空参数。
第二种是调用父类的构造器,注意此处可以是空参数,也可以传入参数。
概述:构造方法是一个特殊的类成员方法,它被用来创建生成对象。当系统识别到关键字new后会去执行指定的构造方法来创建对象。
构造方法注意点:
构造方法重载时可以使用关键字this来替代本类中的其他构造方法。
案例(example)
1 | public class Student{ |
this关键字不仅可以用来指代本类中的构造方法,还可以指代本类中的其他元素它被看成是当前类的运行时对象。
上例中的this.name 如果参数名和类成员变量名不冲突时可以省略this 关键字。
总结点:
在java中使用构造方法是生成实例对象的唯一途径,这个过程称为对象的实例化。
实例化对象时如果对象的成员变量没有显示声明值时,java会默认为其初始化值。如下表所示
| 名称 | 默认值 |
|---|---|
| 数值变量 | 0 |
| 布尔变量 | false |
| 引用变量 | null |
书写语法:
修饰符 返回类型 方法名(参数列表) {
方法体(块)
}
方法定义的注意事项:
方法的重载简单的说就是同一个方法名拥有不同的参数列表
注意事项:
简介:java中静态成员是不依赖于对象内容的。也就是说静态的成员和对象无关。
不同对象的成员,其内存地址是不同的。但是如果类中包含静态成员,则系统只在类定义时为静态成员分配内存。此时还没有创建对象(没有对类进行实例化)以后生成该类的实例时,将不再为静态成员分配内存,不同的对象静态成员是共享的。
在java中静态成员变量是唯一能为类中所有对象共享变量的方法。
注意事项:
简介:java中的包装类是用来将基本类型转换成引用类型操作的实现。
| 基本数据类型 | 包装类 |
|---|---|
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| char | Char |
| boolean | Boolean |
| void | Void |
注意 Void 类不能被实例化
自动装箱
example:
1 | // Integer a =10; |
自动拆箱
1 | // Integer a =10; |
简介:数组是用来表示一些相同数据类型的元素的集合。
注意事项(warning)
案例example
1 | //方式1 |
1 | int intArray[5]; |
简介:数组初始化的过程就是数组的创建过程
注意事项:
案例example
1 | int intArray[] = {1,2,3,4}; |
案例example
1 | String names[]; |
注意事项:
1 | Object[] points; |
1 | Point[] points; |
1 | String names[]; |
简介:多维数组可以理解为数组的嵌套
例如二位数组就是一个多维数组,它的表示方式如下
1 | int[][] intArray; |
1 | int[][] intArray = {{1,2},{3,4},{5,6}}; |
1 | int[][] a = new int[2][3]; |
1 | //矩形多维数组 |
1 | int[][] intArray = {{1,2},{3,4},{5,6}}; |
因为我们平时使用的都是数组的引用,所以我们可以通过改变引用指向的数组来解决这一问题。
案例example
1 | public void changeLengthOfArray(int[] array){ |
System.arraycopy
java.util.Arrays 下的一些静态方法
简介:java中的字符串是由有限个字符组成的序列对象。说到字符串不得不说String 和StringBuffer
注意事项(warning):
常量
1 | "Hello world!" |
变量
1 | String s = new String("Hello World"); |
1 | StringBuffer sb = new StringBuffer("Hello World"); |
1 | StringBuilder sb = new StringBuilder("Hello World"); |
(1)如果要操作少量的数据用 String
(2)多线程操作字符串缓冲区下操作大量数据 StringBuffer
(3)单线程操作字符串缓冲区下操作大量数据 StringBuilder。
== 、compareTo()、equals()、equalsIgnoreCase()、regionMatches()
注意事项:
简介:简单的说可以理解为一个动态数组的实现类
注意事项:
案例example
1 | class MyVector extends Vector{ |
简介:子类是继承父类的衍生类。
子类在程序设计上体现了继承的特点,除使用了面向对象继承的特性外,它还实现了代码的复用性。
语法:
修饰符 class 子类名 extends 父类名{
}
父类的称呼: 超类、基类
继承的关系体现使用is a 可以很贴切的描述出。
案例example:
如员工(employee)和经理(manager)之间的关系就可以使用is a 来描述。
The manager is an employee of the company
模块的概念可以使用 has a 来描述比较贴切。
案例example:
Cars has engines and wheels
发动机和轮胎之间是没有关联的,但是它们都与汽车有联系。所以可以被看做是汽车的模块。
object在java中是所有类的超类
object中的一些常用的方法:
public final class getClass(); 获取当前对象的所属类信息。
public String toString(); 获取当前对象的输出信息。
public boolean equals(Object o); 对象对比时会参看此方法的返回值。
多重继承关系类似于一个网络。如果子类的多个父类中有同名的方法和属性,那么就容易造成子类实例的混乱。
java使用单继承规避了这一缺点,同时通过实现多个接口也可以间接的实现多重继承的优势。
虽然继承可以保留父类中的成员方法和成员变量,但是子类不能继承父类的构造方法。要想使用父类的构造方法可以使用super关键字
案例example
1 | class Employee{ |
子类不能直接访问其父类中定义的私有成员
example:
1 | public class A extends B{ |
简介:和大多数面向对象的语言一样,java允许使用对象的父类类型做引用类型(静态类型),子类对象的实例做值(动态类型)。
example:
1 | B a = new A(); |
但是相反子类类型做引用类型,父类对象做值就会出错是不可以的
example:
1 | A b = new B(); |
简介:方法的覆盖也被称为:override、方法重写、隐藏。它只出现在子父类中。并且要求方法名参数列表和返回值一致。
注意事项:
出于安全考虑,java对于对象的初始化要求是非常严格的。比如,java要求一个父类对象要在子类运行前完成初始化。
虽然不能继承父类中的构造方法,但使用super关键字可以调用父类的构造方法
注意事项:
简介: java中多态是一个非常重要的概念。有了多态,能够允许同一条方法在不同的上下文环境中做不同的事情。
重载方法可以看做是多态的一种形式。
父子类间的override也是多态的一种表现形式。
如 父类类型 a = new 子类类型 ,java 在这种情况下执行override方法,执行的是子类对象中的方法(运行时类型),而不是引用类型(父类/编译时类型)中的方法。
静态类型:引用类型,是在编译时确定下来的。
example:
1 | SuperClass superc; //静态类型 |
动态类型:运行时某一时刻引用所指向对象的类型,它会随着进程的改变而改变。
1 | SuperClass superc = new SuperClass(); //中的 new SuperClass() 对象是动态类型 |
动态绑定:调用稍后可能被覆盖的方法的这种处理方式,称为动态绑定。
静态绑定:在编译过程中能确定调用方法的处理方式,称为静态绑定。
java中有一个关键字final表示终极,它可以修饰类、方法、变量。
当final修饰类时它被称为终极类,这时类不能被继承。
当final修饰方法时它被称为终极方法,此时方法不能被覆盖(override)。
当final修饰变量时它被称为终极变量,此时变量的值不能被修改。
语法:
final public class 类名{
}
1 | final public class FinalClass{ |
语法:
final 权限修饰符 返回值类型 方法名(参数列表){
}
1 | final public void finalMethod(){ |
语法:
final 访问权限修饰符 类型 变量名 = 值;
1 | final int iFinal = 10; |
java中使用abstract 关键字来表示抽象,它可以修饰类、方法。
注意事项:
语法:
abstract public class 类名{
}
1 | abstract public class AbClass{ |
abstract 权限修饰符 返回值类型 方法名(参数列表);
1 | abstract public class AbClass{ |
简介:接口是体现抽象的另一种形式,可将其想象为一个“纯”的抽象类。
语法:
修饰符 interface 接口名{
}
注意事项:
在java接口的定义中默认缺省final public abstract 关键字。如下例子中是一样的。
1 | interface Shape2D{ |
等同于
1 | public interface Shape2D{ |
数据流的来源:
所有的程序都离不开信息的输入输出。比如从键盘上输入一个字符,从文件中读取一行文字。显示器上的文字输出等这都涉及到了信息的输入输出。在java中把这些不同类型的输入或输出源抽象为流(Stream)。
数据流(Data Stream)
数据流是指一组有序的、有起点和终点的字节集合。例如使用键盘写数据到文件中,此操作可以使用数据流来完成。
java.io包下的文件提供了流基础的使用支持。其中最常用的分为 (InputStream ,OutputStream)和(Reader,Writer)inputStream outputStream 用来处理字节流,Reader Writer 用来处理字符流。
简介:输入数据流是指只能读取不能写的数据流,用于向计算机内输入数据。
java.io包下有关输入数据流的类都直接或间接继承于InputStream抽象类。
InputStream抽象类中提供的数据主要操作方法如下:
使用输入数据流时的注意事项:
简介:输出数据流是指,能将计算机内的数据输出到指定的数据源中,但是不能读取数据源中的数据。用于计算机内的数据输出。
与输入数据流InputStraem流类似,java.io包下的输出数据流实现类都直接或间接继承于OutputStream.
OutputStream 抽象类中提供了如下数据流的操作方法:
使用输出数据流时的注意事项:
FileInputStream
FileOutputStream
案例example:
1 | public class FileOutputStreamTest { |
简介:过滤器(filter)流,它是数据流的一个装饰流。如:BufferedInputStream BufferedOutputStream 等。
BufferedInputStream
BufferedOutputStream
构造方法:
1 | public BufferedInputStream(InputStream var1)// 使用默认的缓存区8192创建 |
DataInputStream
DataOutputStream
构造方法:
1 | public DataInputStream(InputStream var1) |
1 | public static void learnDataOutputStream(){ |
DataInputStream or DataOutputStream 使用注意事项:
简介:主要用来保存某一时态时的对象状态
ObjectInputStream
ObjectOutputStream
注意事项:
案例example:
1 | public class Student implements Serializable { |
1 | public static void studyObjectInputStream(){ |
Reader and Writer.
java.io包中的Reader和Writer的抽象类是所有字符流处理的超类.
java同其他程序设计(programming)语言使用的字符集不同。java采用Unicode 而大多数老式编程语言如c采用ASCII.
ASCII 使用一个字节(8bit)表示一个字符,而Unicode使用两个字节(16bit)表示一个字符.
字符流输入处理实现类,它可以设置处理字符的字符集
构造方法:
1 | public InputStreamReader(InputStream var1, String var2) |
字符流输出处理实现类,它可以设置处理字符的字符集
构造方法:
1 | public OutputStreamWriter(OutputStream var1, String var2) |
带缓存的读者类
带缓存的写者类
java中的文件处理主要使用java.io.File类
1 | public static void studyFile(){ |
指定位置的访问文件类
1 | public static void studyRandomAccessFile(){ |
knowledge point:
1.图形用户界面(Graphical user interface )简称GUI。
2.java.awt 或 javax.swing包含了多种用于创建图形用户界面的组件类
3.设计用户图形界面的步骤,选取组件——》设计布局——》响应事件
4.awt 与swing组件最大的不同是swing组件在实现时不包含任何本地代码,因此swing组件可以不受硬件平台的限制。所以swing组件也被称为”轻量级”组件,而包含本地代码的awt被称为”重量级”组件。
5.当重量级组件与轻量级组件一同使用时,如果组件区域有重叠,则”重量级”组件总是显示在最上面。
6.组件是构成图形用户界面的基本元素。如JButton、JTextField等。
7.组件可以划分为容器组件和非容器组件。
knowledge point:
1.容器组件是指可以包含其他组件的组件。
2.容器可以分为顶层容器和一般容器。
3.显示在屏幕上的所有非容器组件必须包含在某个容器中,有些容器是可以嵌套的,在这个嵌套层次的最外层,必须是一个顶层容器。
4.Java为所有容器定义了父类Container。
5.Swing 提供了4种顶层容器,分别为JFrame、JApplet、JDialog、JWindow。
6.关于JFrame 的example:
1 | package chapter8; |
knowledge point:
1.获取内容窗格的2种方式:
a).JFrame下的getContentPane()
b).new JPanel,然后将新创建的JPanel通过JFrame的setContentPane放入。
knowledge point:
1.JPanel普通面板 ,JScrollPane滚动面板
2.面板不能单独存在,它需要被放入到顶层容器中,并且它自身是可以嵌套的。
3.关于面板的example:
1 | JFrame frame = new JFrame("Frame with Panel and scrollPane"); |
knowledge point:
1.JLable 标签类。
example:
1 | JFrame frame = new JFrame("JFrame with JLabel"); |
knowledge point:
JButton
1 | JFrame frame = new JFrame("JFrame Dome"); |
knowledge point:
1.JToggle
example:
1 | package chapter8; |
knowledge option:
1.JCheckBox
knowledge option:
1.JRadioButton
2.需要加入按钮组从而保证只有一个选项被选中
example:
1 | package chapter8; |
knowledge option:
1.布局用来管理容器中各组件的位置分布。
knowledge option:
1.JPanel 的默认布局方式就是流式布局
流式布局如下代码所示
1 | package chapter8; |
knowledge option:
1.内容窗口的默认布局为Border layout
borderlayout布局如下代码所示
1 | package chapter8; |
knowledge option:
Gridlayout 是一种网格式的布局管理器,它将容器空间划分成若干行乘若干列的网格,组件依次放入其中,每个组件占一格。
example:
1 | package chapter8; |
knowledge point:
card layout 是一种卡片式布局管理器,它将容器中的组件处理为一系列的卡片,每一时刻显示其中的一张。
1 | package chapter8; |
knowledge point:
boxLayout 是一种特殊的布局管理器,它将容器中的组件按照水平方向组成一行,垂直方向组成一列。当组成行时,组件与组件间可以设定不同的宽度,当组成列时组件与组件间可以有不同的高度。
example:
1 | package chapter8; |
knowledge point:
空布局就是不使用布局,通过组件中的setBounds方法来设定组件的位置和大小。
example:
1 | package chapter8; |
knowledge point:
用户事件:程序里用户的操作称为用户事件。
事件处理:对用户事件的响应称为事件处理
| 事件类型 | 组件 | 接口名称 | 方法及说明 |
|---|---|---|---|
| action event | JButton、JCheckBox、JComboBox、JMenuItem、JRadioButton | ActionListener | actionPerformed(Action Event)单机按钮、选择菜单 项目或在文本框中按enter键时 |
knowledge point:
适配器主要是针对接口使用的优化,它实现了多个接接口,但是方法体内是空的,自己使用时只需要继承它并重写需要使用的方法。
1 | package chapter9; |
1 | package chapter9; |
1 | package chapter9; |
1 | package chapter9; |
1 | package chapter9; |
1 | package chapter9; |
knowledge point:
1.进程可以大致描述为,占用系统资源的一个程序。
2.线程是进程中的产物。
3.多个线程共享进程中的资源。而多个进程未必共享指定的系统资源。
4.进程是有入口和出口的,而线程则没有,它需要依附于进程中的主线程或其余线程启动。
5.线程间的切换速度高于进程间的切换速度。
6.多线程程序可以充分利用系统资源,特别是CUP的使用效率。从而提高程序的整体执行效率
7.Java中的线程执行顺序是抢占式的,而不是时间碎片式。
knowledge point:
java中线程由以下3部分组成:
1.虚拟CPU,封装在java.lang.Thread 类中,它控制着整个线程的运行。
2.执行代码,传递给Thread类,有Thread类控制按序执行。
3.处理的数据,传递给Thread类,是在代码执行过程中所要处理的数据。
knowledge point:
线程的状态分为:
1.新建 :线程对象刚刚创建,还没有启动。此时还处于不可运行状态。此时刚创建的线程处于新建状态,但已有了相应的内存空间以及其他资源。
2.可运行状态:此时的线程已经启动,处于线程的run()方法之中。这种情况下的线程可能正在运行,也可能没有运行。只要CPU一空闲,马上就会运行。可以运行但没有在运行的线程都排在一个队列中,这个队列称为就绪队列。可运行状态中,正在运行的线程处于运行状态,等待运行的线程处于就绪状态。一般的,单CPU情况下,最多只有一个线程处于运行状态,其余队列中的等待的线程处于就绪状态。
3.死亡:线程死亡的原因有两个,1是run方法中最后一个语句执行完毕,2是当线程遇到异常退出时便进入了死亡状态。
4.阻塞:阻塞状态时的线程不能进入等待队列,需要消除阻塞原因才可以进入等待队列,因被抢占而阻塞的线程会被放置队列的尾部
5.中断线程:程序中使用Thread下的interrupt方法来终止线程。它不仅可以终止平常线程而且还可以终止blocked线程
knowledge point:
1.通过继承Thread类并重写run方法来实现
2.通过实现Runnable,并将其放入Thread类中实现
评价:第一种方法方便灵活,当时局限于Java的单继承。第二种方法可以弥补第一种方法的缺陷。
通过创建线程对象然后调用其start方法
knowledge point:
1.Java中,线程的调度通常是抢占式的,而不是时间碎片式。
2.java线程调度采用的优先策略规则:
3.Thread类与线程有关的静态变量,如下:
4.Thread类中有关优先级的几个常用方法如下:
knowledge point:
自然死亡:线程体run方法内的代码执行完毕。
强迫死亡:因异常而终止的情况下。
interrupt 可以中断线程的执行
knowledge point:
sleep
wait notify notifyAll
join
互斥的由来:
通常情况下,一些运行的线程需要共享一些数据。此时,每个线程就必须要考虑与它一起共享数据的其他线程的状态与行为,否则就不能保证共享数据的一致性。因而也不能保证程序的正确性。
举例说明:
假设有一个MyStack类,类中的index是多个线程要操作的公共资源。如果不加对象互斥锁
可以发现,输出的信息中出现了线程并发修改index的情况。
总结:导致上述案例出现问题的原因是“对公共资源操作的不完整性”而产生的。
如何解决上述问题呢?答案是使用对象互斥锁
java中实现对象互斥锁的方法:
knowledge point:
实现线程互斥时,run方法内操作的内容需要是多个线程共享的,static修饰可实现。如果其中的内容是属于每个线程对象的,则不能实现线程的互斥。也就是说想要被互斥的代码块必须是多个线程共享的内容。
sleep 方法不会释放锁。而wait()会释放锁
example:
1 | package chapter10; |
1 | package chapter10; |
线程同步的由来:
主要是为了实现线程间的交互。
案例说明:
如,现在我们有3个类 生产者(producer)消费者(consumer)容器(Container),现在有一个需求,操作流程是这样的。生产者需要生产10个盘子(plate)到容器中,而消费者需要消费容器中的盘子。运行条件是1个消费者 2个生产者1个容器。要求用程序来模拟这个情景
knowledge point:
java中的每个对象实例都有2个线程队列和它相连。第一个是用来排列等待锁定标志的线程。第二个用来实现wait()和notify/notifyAll的交互机制
wait、notify、notifyAll 只能在synchronized代码块中使用。
1 | package chapter10; |
1 | package chapter10; |
1 | package chapter10; |
1 | package chapter10; |
import static静态导入是JDK1.5中的新特性。
一般我们导入一个类都用 import 包名.类名;
而静态导入是这样:import static 包名.类名.*;
这里的多了个static,还有就是类名后面多了个 . 。意思是导入这个类里的静态成员(静态方法、静态变量)。当然,也可以只导入某个静态方法,只要把 . 换成静态方法名就行了。然后在这个类中,就可以直接用方法名调用静态方法,而不必用“类名.方法名()” 的方式来调用。
这种方法的好处就是可以简化一些操作,例如一些工具类的静态方法,如果使了静态导入,就可以像使用自己的方法一样使用这些静态方法。
不过在使用静态导入之前,我们必须了解下面几点:
1.什么是磁盘分区:
磁盘分区是使用分区编辑器(partition editor)在磁盘上划分几个逻辑部分,碟片一但划分成数个分区(partition)不同类的目录与文件可以存储进不同的分区。
example:
划分柜子,将一个大柜子划分为3个小柜子。这样可以方便使用者。
分区类型:
主分区:最多只能有4个(一块硬盘的前提条件下)
扩展分区:
最多只能有1个(一块硬盘的前提条件下)
主分区加扩展分区最多有4个(一块硬盘的前提条件下)
不能写入数据,只能包含逻辑分区(一块硬盘的前提条件下)

逻辑分区
2.格式化
什么是格式化:
格式化 (高级格式化)又称逻辑格式化。它是指根据用户选的的文件系统(FAT16、FAT32、NTFS、EXT3、EXT2、EXT4等)在磁盘的特定区域写入特定数据,在分区中划出一片用于存放文件的分配表、目录表等用于文件管理的磁盘空间。
Linux默认的文件系统:EXT4
关键词:
block
inode 号
3.硬件设备文件名

4.分区设备文件名

/dev/hda1 代表什么? /dev 代表了这是系统的设备文件的根目录,hda1中hda表示用户使用的是IDE硬盘,1表示第几个分区(数字标识)
IDE硬盘接口:

理论每秒传输133MB
SCSI硬盘接口:

理论每秒传输200MB
SATA硬盘接口:

sata3代理论每秒传输500MB
5.挂载
必须分区
/(根分区)
swap(交换分区、内存2倍)
推荐分区
/boot(启动分区,200MB)
文件系统结构

系统分区流程
分区 》格式化 》为分区指定设备文件名 》 挂载
复杂性
八位字符以上、大小写字母、数字、符号
不是单词
不是用户的相关信息
易记性
时效性
/root/install.log 存储了安装在系统中的软件包及其版本信息
/root/install.log.syslog 存储了安装过程中留下来的事件信息
/root/anaconda-ks.cfg 以Kickstrat配置文件的格式记录安装过程中设置的选项信息
ifconfig :查看系统网卡信息
ifconfig eth0 [ip 地址] :临时配置网卡,系统重启后失效
严格区分大小写
Linux中所有的内容都是以文件形式保存,包括硬件
硬盘文件是/dev/sd[a-p]
光盘文件是/dev/sr0等
Linux不靠扩展名区分文件类型
Linux所有存储设备都必须挂载之后用户才能使用,包括硬盘、U盘和光盘
windows下的程序不能直接在Linux中安装和运行
服务器最好重启操作,不要关机操作
重启时应该关闭服务器
不要在服务器访问高峰运行高负载命令
远程配置防火墙时不要把自己踢出服务器
指定合理的密码规范并定期更新
合理分配权限
定期备份重要数据和日志
推荐的方式执行任何Gradle构建的帮助下Gradle包装器(总之只是“包装器”)。包装是一个脚本,该脚本调用它宣布版本,必要时预先下载它。因此,开发人员可以用Gradle项目迅速而不必遵循手动安装过程节省贵公司的时间和金钱
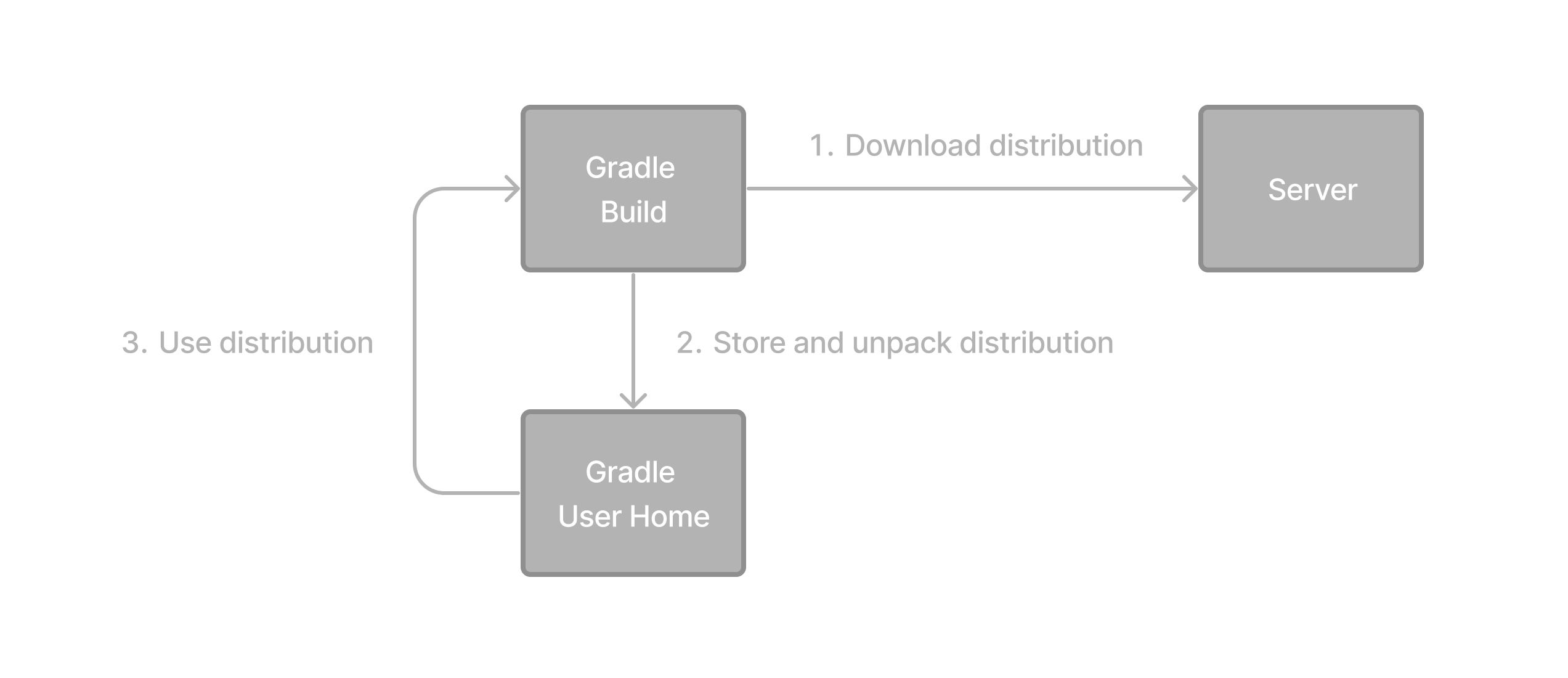
你将获得以下好处:
同一版本
减低了版本统一的维护成本,只需在wrapper 文件下声明处修改版本就可以
1 | task wrapper(type: Wrapper) { |
在自己指定的工作空间目录下运行如下命令
1 | gradle wrapper |
创建指令
–gradle-version :用于指定gradle 的版本
–distribution-type :用于指定gradle的类型 bin 或 all
–gradle-distribution-url : 用于指导gradle的下载路径
–gradle-distribution-sha256-sum :用于指定编码格式
案例:创建gradle 版本为5.1.1的all类型
1 | gradle wrapper --gradle-version 5.1.1 --distribution-type all |
创建后的目录结构图
1 | ├── gradle |
gradle-wrapper.jar wrapper的源文件
gradle-wrapper.properties wrapper的版本等配置属性
gradlew shell脚本工具
gradlew.bat windows 批处理工具
在项目目录下运行下列代码
1 | gradlew.bat build |
使用前面的命令可进行更新
1 | gradle wrapper --gradle-version 5.1.1 |
如何去做用户管理
越是对服务器安全性要求高的服务器,越需要建立合理的用户权限等级制度和服务器操作规范。
在Linux中主要是通过用户配置文件来查看和修改用户信息。
这个 文件 中 保存 的 就是 系统 中 所有 的 用户 和 用户 的 主要 信息。
文档解读:
文件中一行代表一个用户,每行分为7个字段,下面解释下这7个字段分别附有什么含有
1.用户名称
2.密码标识 ,具体密码信息需要进入/etc/shadow查看,并且密码采用SHA512散列加密算法.
3.uid 用户的id标识 0表示超级用户,而且前499已经被系统占用
4.gid 表示用户组id标识 这里指的是用户的初始组
5.用户说明信息
6.用户的home 目录
7.用户登陆后所能执行的shell脚本
文件中存储了关于用户的密码的一些信息
同样每行表示每个用户的密码信息,每行分为6个字段
1.用户名称
2.密码 经过加密后的,被锁定的密码前会加入!!
3.密码最后一次修改日期
4.密码的两次修改时间间隔(和3做比较)
5.密码的有效期(和3做比较)
6.密码修改到期前的警告天数(和5做比较)
/etc/group 存储了信息用户组的信息
/etc/gshadow 存储了用户组管理员以及密码的一些信息
具体详情 可查阅 man 5 gshadow
1.用户的家目录
/home/用户名称 或/root/
2.用户邮箱目录
/var/spool/mail/用户名称
3.用户模板目录
/etc/skel
添加用户 useradd [选项] 用户名
指定修改用户密码 passwd [选项] 用户名
修改用户信息 usermod [选项] 用户名
删除用户 userdel [选项] 用户名
切换用户 su [选项] 用户名
“-” 切换后使用切换用户的环境
“-c” 仅执行一次命令
添加用户组 groupadd [选项] 组名
修改用户组 groupmod [选项] 组名
删除用户组 groupdel [选项] 组名
把用户加入组中 gpasswd 选项 组名
“-a” 用户名 把用户加入组
“-d”用户名 把用户从组中删除
Base64是一种用64个字符来表示任意二进制数据的方法。
用记事本打开exe、jpg、pdf这些文件时,我们都会看到一大堆乱码,因为二进制文件包含很多无法显示和打印的字符,所以,如果要让记事本这样的文本处理软件能处理二进制数据,就需要一个二进制到字符串的转换方法。Base64是一种最常见的二进制编码方法。
Base64的原理很简单,首先,准备一个包含64个字符的数组:
['A', 'B', 'C', ... 'a', 'b', 'c', ... '0', '1', ... '+', '/']
然后,对二进制数据进行处理,每3个字节一组,一共是3x8=24bit,划为4组,每组正好6个bit:
这样我们得到4个数字作为索引,然后查表,获得相应的4个字符,就是编码后的字符串。
所以,Base64编码会把3字节的二进制数据编码为4字节的文本数据,长度增加33%,好处是编码后的文本数据可以在邮件正文、网页等直接显示。
如果要编码的二进制数据不是3的倍数,最后会剩下1个或2个字节怎么办?Base64用\x00字节在末尾补足后,再在编码的末尾加上1个或2个=号,表示补了多少字节,解码的时候,会自动去掉。
1 | base64.b64encode(b'binary\x00string') |
1 | base64.b64decode(b'YmluYXJ5AHN0cmluZw==') |
由于标准的Base64编码后可能出现字符+和/,在URL中就不能直接作为参数,所以又有一种"url safe"的base64编码,其实就是把字符+和/分别变成-和_
1
base64.urlsafe_b64encode(b'i\xb7\x1d\xfb\xef\xff')
以上内容参考https://www.liaoxuefeng.com/wiki/1016959663602400/1017684507717184
1 | [root@bogon ~]# |
如上所示:
[] :是centos的提示分隔符,没有特殊的意义
root :表示当前的登录用户
@ :表示分隔符号,没有特殊的意义
bogon : 表示当前系统的简写
~ :表示当前用户所在的目录,~就是当前用户的家(home)目录
# : 命令提示符,可以标识当前登录用户的权限等级,普通用户使用$标识,超级管理员用#标识

选项存在2种格式
1.长格式选项 如:--all
2.短格式选项 如:-a

使用 -a 时会看到有的文件名前有.此时表示此文件为隐藏文件。
使用-l 查看详细信息

上面1表示此文件的链接计数

上面的root 表示文件的所有者,也就是文件的创建人或负责人,一个文件只能有一个所有者

上面表示文件的所属组,一个文件只能拥有一个所有组
在-l 后追加h -lh 表示人性化显示,使文件的大小更直观、

ls -i 可以获取文件的I节点或获取文件的id号


cd - 回到上次操作的目录
cd ~ 回到当前用户的根目录
cd 回到当前用户的根目录





tree 命令以目录树的方式显示文件结构信息
使用tree 时可能会遇到command not found ,这时就需要安装此命令
本人使用的是centos 7 的系统 发现使用yum 无法获取tree的安装包
所以只能使用源码包安装,于是在ftp://mama.indstate.edu/linux/tree/ 下载了 源码包
在/usr/local/src 下使用make 编译了源码包


cat 适用于查看简短文件内容,如shell脚本


less 进入后使用 /关键字 可进行反白关键字高亮显示,同时按N键可以跳到下一个关键字,在高亮的关键字后加入!可以取消高亮效果




硬链接的生成命令
1 | ln /tmp/china/changzhi /root/china.hard |
硬链接 共享文件的inode ,但是文件夹不能创建硬链接。
权限分为了三类 r w s 读 写 执行









-name 加通配符可实现模糊搜索文件
通配符 * 表示多个字符
通配符 ?表示单个字符




此查询基于文件资料库所以,查询时对比find占用系统资源较少。
存在缺陷无法查询tmp目录下的文件
不能实时查询,如果刚创建的数据没有录入文件资料库时。会导致无法查询到文件。此时使用命令
1 | updatedb |
然后再次使用 locate可查找到文件




帮助命令类型 1表示命令,5表示配置文件
命令名称:whatis
NAME
whatis - 在 whatis 数据库里查找完整的单词
总览 (SYNOPSIS)
whatis keyword …
描述 (DESCRIPTION)
whatis 命令在一些特定的包含系统命令的简短描述的数据库文件里查找关键字, 然后把 结果送到标准输出。 查找的内容必须完全匹配关键字的才会输出。 whatis 数据库文件是用 /usr/sbin/makewhatis 命令建立的。
参见 (SEE ALSO)
apropos(1), man(1).
[中文版维护人]
唐友 tony_ty@263.net
[中文版最新更新]
2001/9/8
[中国Linux论坛man手册页翻译计划]
http://cmpp.linuxforum.net
命令名称:apropos
NAME
apropos - 在 whatis 数据库中查找字符串
总览 (SYNOPSIS)
apropos keyword …
描述 (DESCRIPTION)
apropos 命令在一些特定的包含系统命令的简短描述的数据库文件里查找关键字, 然后把 结果送到标准输出。
参见 (SEE ALSO)
whatis(1), man(1).
[中文版维护人]
唐友 tony_ty@263.net
[中文版最新更新]
2001/9/20
[中国Linux论坛man手册页翻译计划]
http://cmpp.linuxforum.net







gz zip rar 其中 zip 是windos和Linux 都支持的压缩格式


gzip的缺陷就是目前只能压缩文件,并且压缩后是不保留源文件的。

tar 格式表示打包



unzip 解压文件时出现乱码如何解决,使用命令 unzip -O CP936 压缩包名称 即可。其中-O表示知道文件的编码集,
CP936是IBM code page 中的第936页也就是咋们俗称的GBK。



rar 格式的文件解压或压缩1
2
3
4
5#安装rar shell脚本
sudo apt install rar
rar x 文件名进行解压
更多信息使用 man rar





mail 命令操作时需要使用CTRL+D 才可生效,如执邮件的删除功能,需要除了使用delete命令后还需使用
CTRL+D才可。
mail 进入使用界面后, h表示查看列表,d表示删除指定的邮件













修改系统默认运行级别代码
1 | init 2 |

查看系统存储信息1
/proc/meminfo
java jdk版本切换1
jdk 版本切换:sudo update-alternatives --config java
1 | ps aux |grep java |
简介:nohup 命令运行由 Command参数和任何相关的 Arg参数指定的命令,忽略所有挂断(SIGHUP)信号。在注销后使用 nohup 命令运行后台中的程序。要运行后台中的 nohup 命令,添加 & ( 表示“and”的符号)到命令的尾部。
nohup 是 no hang up 的缩写,就是不挂断的意思。
nohup命令:如果你正在运行一个进程,而且你觉得在退出帐户时该进程还不会结束,那么可以使用nohup命令。该命令可以在你退出帐户/关闭终端之后继续运行相应的进程。
在缺省情况下该作业的所有输出都被重定向到一个名为nohup.out的文件中。
关键词:0 – stdin (standard input),1 – stdout (standard output),2 – stderr (standard error) ;
案例:
1 |
|
上面的案例表示以不挂断的形式执行MM3Spider.py文件 并将标准异常流(standard error)输入到标准输出流中,并且将标准输出流的信息输入 python_info.log文件中
简介:后台执行某段命令
&是指在后台运行,但当用户推出(挂起)的时候,命令自动也跟着退出,nohup : 不挂断的运行,注意并没有后台运行的功能,,就是指,用nohup运行命令可以使命令永久的执行下去,和用户终端没有关系,例如我们断开SSH连接都不会影响他的运行,注意了nohup没有后台运行的意思;&才是后台运行
通常我们组合使用如下
1 |
|
简介: print system information
-a, –all
print all information, in the following order, except omit -p
and -i if unknown:
1 | uname -a |